Googlebot cannot access CSS and JS on your Drupal site
There was a time when search engine bots would come to your site, index the words on the page, and continue on. Those days are long past. Earlier this year, we witnessed Google's ability to determine if our sites were mobile or not. Now, the evolution of the Googlebot continues.
I would say that it was not uncommon for web developers to receive at least a few emails from Google Search Console today.
To: Webmaster...
Google systems have recently detected an issue with your homepage that affects how well our algorithms render and index your content. Specifically, Googlebot cannot access your JavaScript and/or CSS files because of restrictions in your robots.txt file. These files help Google understand that your website works properly so blocking access to these assets can result in suboptimal rankings.
Well, that's a little bit of information that I never thought about before, Google wanting to understand, how my "website works", not just understanding the content and the structure of it. Turns out, Google has been working toward this since October of last year.
Update your robots.txt
To allow Googlebot to access your Javascript and CSS files, add a specific User-agent for Googlebot, repeating the rules you already have, and adding the new "Allow" rules.
Allow: /*.js*
Allow: /*.css*
Allow: /misc/*.js
Allow: /modules/*.js
Allow: /modules/*.css
User-agent: *
# Directories
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /profiles/
Disallow: /scripts/
Disallow: /themes/
# Files
Disallow: /CHANGELOG.txt
Disallow: /cron.php
Disallow: /INSTALL.mysql.txt
Disallow: /INSTALL.pgsql.txt
Disallow: /INSTALL.sqlite.txt
Disallow: /install.php
Disallow: /INSTALL.txt
Disallow: /LICENSE.txt
Disallow: /MAINTAINERS.txt
Disallow: /update.php
Disallow: /UPGRADE.txt
Disallow: /xmlrpc.php
# Paths (clean URLs)
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /filter/tips/
Disallow: /node/add/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: /user/login/
Disallow: /user/logout/
# Paths (no clean URLs)
Disallow: /?q=admin/
Disallow: /?q=comment/reply/
Disallow: /?q=filter/tips/
Disallow: /?q=node/add/
Disallow: /?q=search/
Disallow: /?q=user/password/
Disallow: /?q=user/register/
Disallow: /?q=user/login/
Disallow: /?q=user/logout/
User-agent: Googlebot
# Directories
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /profiles/
Disallow: /scripts/
Disallow: /themes/
# Files
Disallow: /CHANGELOG.txt
Disallow: /cron.php
Disallow: /INSTALL.mysql.txt
Disallow: /INSTALL.pgsql.txt
Disallow: /INSTALL.sqlite.txt
Disallow: /install.php
Disallow: /INSTALL.txt
Disallow: /LICENSE.txt
Disallow: /MAINTAINERS.txt
Disallow: /update.php
Disallow: /UPGRADE.txt
Disallow: /xmlrpc.php
# Paths (clean URLs)
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /filter/tips/
Disallow: /node/add/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: /user/login/
Disallow: /user/logout/
# Paths (no clean URLs)
Disallow: /?q=admin/
Disallow: /?q=comment/reply/
Disallow: /?q=filter/tips/
Disallow: /?q=node/add/
Disallow: /?q=search/
Disallow: /?q=user/password/
Disallow: /?q=user/register/
Disallow: /?q=user/login/
Disallow: /?q=user/logout/
# ========================================= #
Allow: /*.js*
Allow: /*.css*
# the most specific rule based on the length of the [path] entry will trump the less specific (shorter) rule.
# The order of precedence for rules with wildcards is undefined
# https://developers.google.com/webmasters/control-crawl-index/docs/robots_txt
# Thanks to Marcel Jong and sunishabraham
Allow: /misc/*.js
Allow: /modules/*.js
Allow: /modules/*.css
# ========================================= #
http://jimbir.ch/sitemap.xml
Starting from the root of the site, /, the first * will take care of the path and file name. The second * will cover any versions or variables that come after the file.
Fetch and Verify
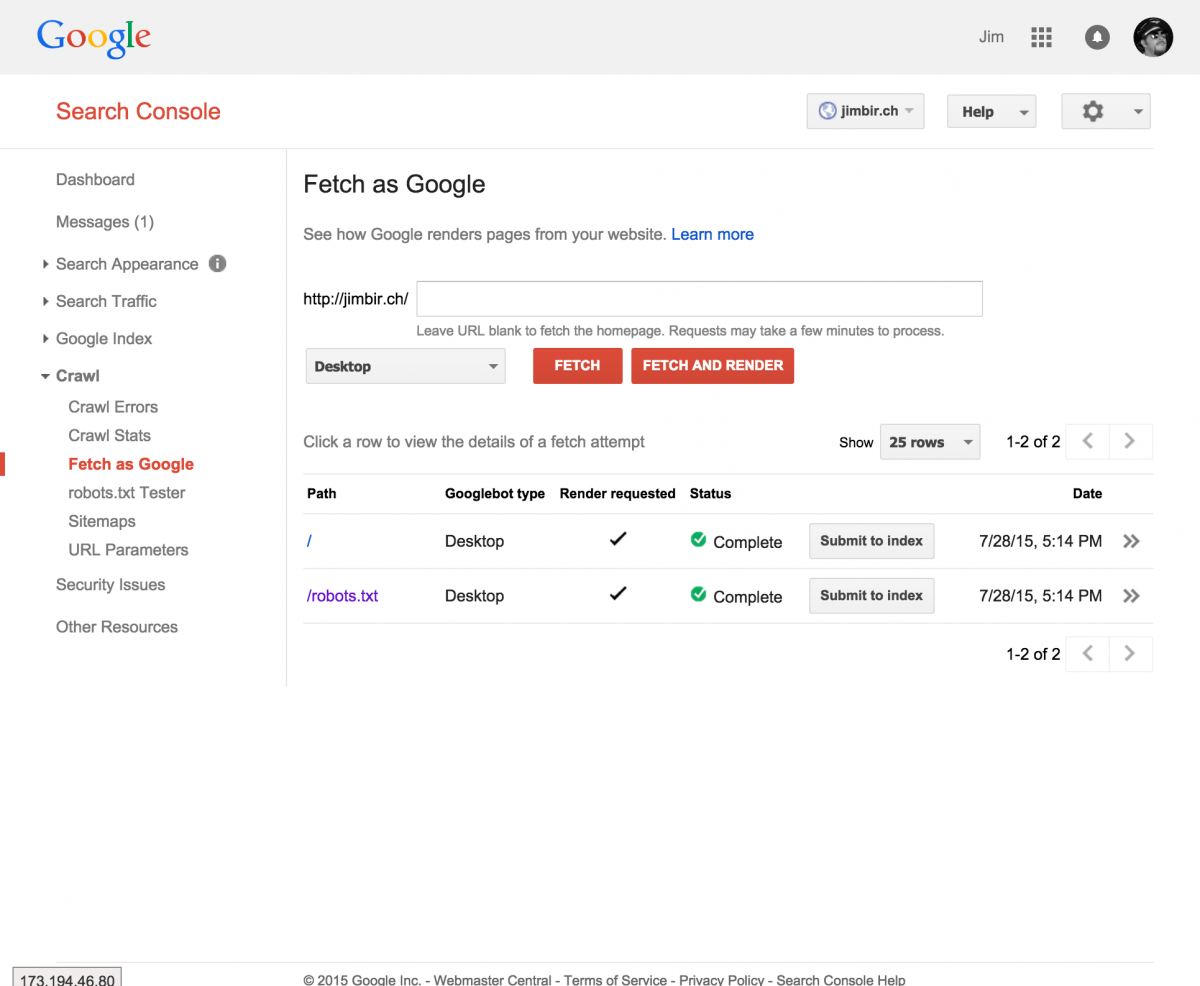
Once you have completed the changed and published to your production server, log into Google Search Console to verify.
- Under Crawl, select Fetch as Google
- Enter robots.txt in the URL box, and click Fetch and Render. Once the query finishes, click on the double arrows >> to verify it grabbed the correct file.
- If all is well, return to the page, and click the Fetch and Render button again to fetch the homepage. Click the double arrows >> to view the results.
If you need to exclude other files, update your robots.txt and start from the first step. If you want to test other pages, repeat step 3 until you are satisfied.
You may get a "Partial" result if you have external scripts, these are scripts that you are loading on your page from other websites or services. I can't think of a solution for that. I find it hard to believe that google will penalize you for not being able to allow them to index those also.
EDIT: David in the comments, and Lorenz by email let me know that there is an active issue on Drupal.org about this at https://www.drupal.org/node/2364343
EDIT 2: I am going to add the Wordpress code here for my convenience.
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/cache/
User-agent: Googlebot
Disallow: /wp-admin/
Allow: /*.js*
Allow: /*.css*
Allow: /wp-admin/admin-ajax.php*
Sitemap: http://www.example.com/sitemap_index.xml